Data Flow and Pipeline Patterns
Patterns Overview
Below we summarize the core patterns that can be used to design and build out your data flows and pipelines.
Important
The documentation for each pattern is accompanied with a data flow example. Please note that:
The examples are designed to relay the key differences between the various patterns
The examples demonstrate the changes to the target tables in Append Only, SCD1 and SCD2 scenarios.
The customer address master table only has a few basic columns so that we can keep the example simple.
Pattern |
Description |
|---|---|
Suitable for: Ingestion and basic 1:1 loads. Usage Scenario:
Layers:
|
|
Suitable for: Multi-source streaming and basic transformations. Usage Scenario:
Layers:
Models:
Considerations & Limitations:
|
|
Suitable for: When you have a streaming table that you need to join to one or many additional static tables to derive your desired target data set. Usage Scenario:
Layers:
Models:
Considerations & Limitations:
|
|
Suitable for: When you have a streaming table that you need to join to one or many additional static tables in order to derive your desired target data set, but you also want updates to the static tables to be reflected as they occur. Usage Scenario:
Layers:
Models:
Considerations & Limitations:
|
|
Suitable for: Constructing a CDC stream from a snapshot source to be used in multi-source streaming or stream-static patterns. Usage Scenario:
|
Patterns Documentation
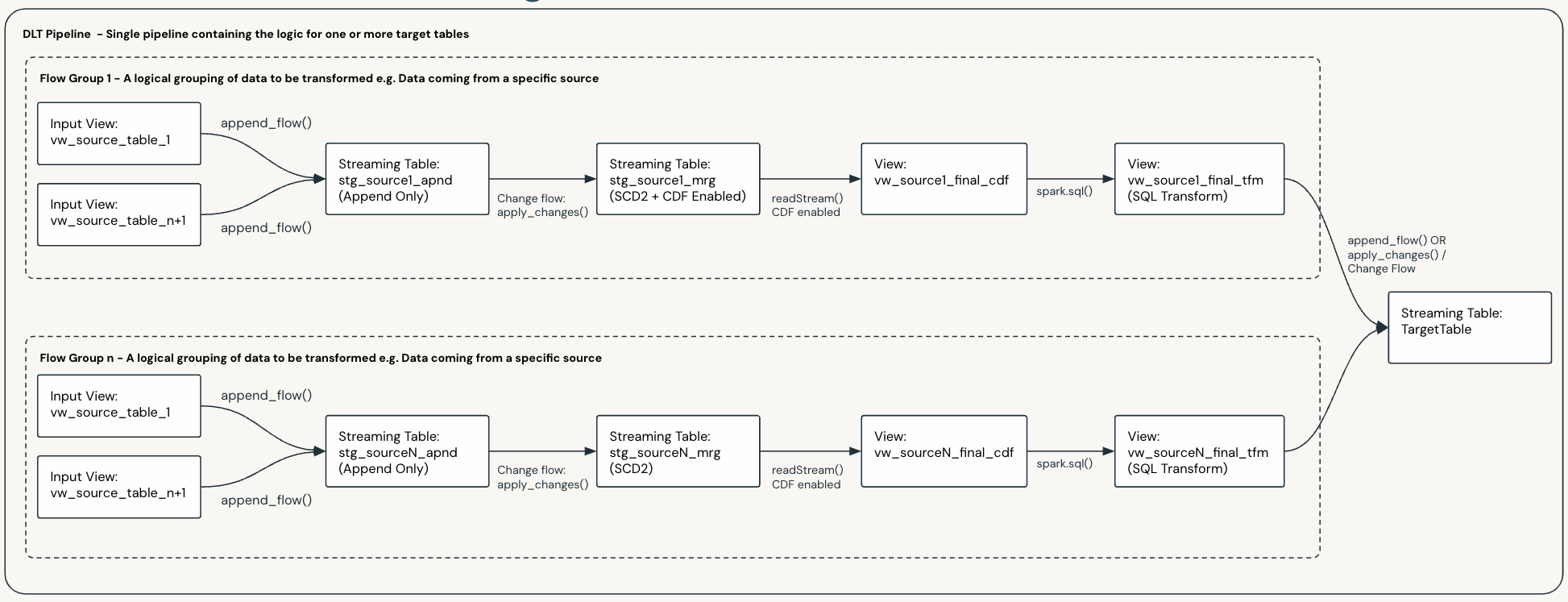
Multi-Source Streaming and Flow Groups
The Multi-Source Streaming feature allows you to stream multiple flows into a single target.
Per the Framework Concepts section of this documentation, Flow Groups are used to logically group flows. This is useful when you have multiple complex sources and makes data flow development and maintenance more manageable.
You can design your pipelines with multiple flow groups, e.g if you have tables from 50 source systems streaming into one target table via a series of different transformations, you would likely design your data flow to have 50 Flow Groups, one for each source.
The diagram below shows a data flow with two flow groups, each with their own flows, and each populating the same target table:
Important
This applies to all data flows and patterns that use Flow Groups.
Important
Per the Framework Concepts section of this documentation, Flow Groups and Flows can be added and removed from a data flow as your requirements and systems evolve. This will not break the existing pipeline and will not require a full refresh of the Pipeline.
Mix and Match
You can have one or more data flows in a single pipeline, and each of these can be based on a different pattern.
You can also mix and match patterns in a single data flow, where you have multiple Flow Groups populating the same target table; as shown below:

Scaling and Pipeline Scope
When designing your data flows and pipelines, you will need to decide how you will scale and scope your data flows and pipelines to support your business requirements.
There is no hard and fast rule in determining how to divide up your pipelines, what you choose will depend on your specific requirements and constraints. The following factors will influence your choice:
Your organizational structure.
Your operational practices and your CI/CD processes.
The size and complexity of your data e.g. the number of sources, transformations, targets and volumes.
Your latency requirements and your SLA’s.
and many more …
Ultimately you will need to determine the best way to divide up your pipelines to support your business requirements.
Important
Per the Framework Concepts section of this documentation:
A data flow, and its Data Flow Spec, defines the source(s) and logic required to generate a single target table.
A Pipeline Bundle can contain multiple Data Flow Specs, and a Pipeline deployed by the bundle may execute the logic for one or more Data Flow Specs.
For the above reasons the smallest possible division for a Pipeline is a single data flow and hence a single target table.
Warning
Be aware of the current Pipeline and concurrency limits for DLT. These are subject to change and you can check the latest limits at:
Pipeline Scope
The most common strategy is to logically group your target tables as a starting point and then determine your pipeline scope from there. Some of the most common groupings are shown below:
Logical Grouping |
Description |
|---|---|
Use Case |
You may choose to have an end to end pipeline for given Use Cases |
Bronze |
|
Silver / Enterprise Models |
|
Gold / Dimensional Models |
|
Once you have determined the best way to divide up your pipelines, you can then determine the best way to implement them, which will fall into one of the following categories:
Decomposing Pipelines
You can break a pipeline down into smaller, more manageable pipelines where natural boundaries exist.
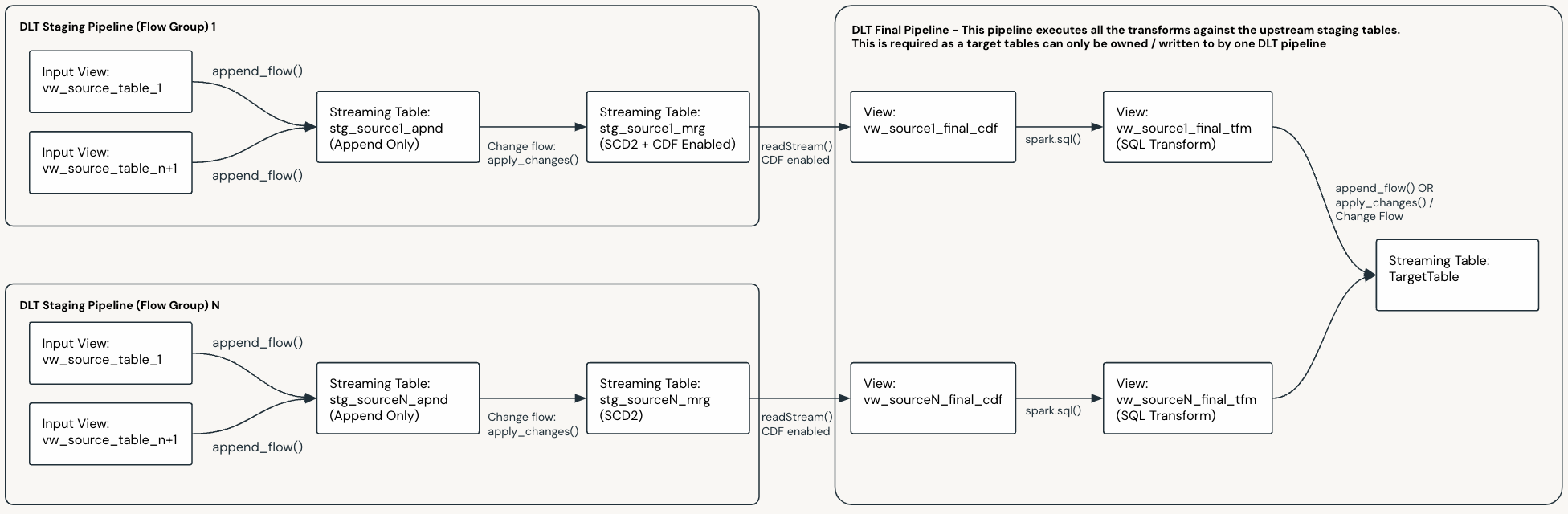
In the below example, we start with a pipeline that has two Flow Groups flowing into a target table, via some staging tables:
Below is the same pipeline decomposed into three pipelines:
Each Flow Group has been broken out into a separate pipeline, the target table of which is the final staging table.
There is a final pipeline that merges the up stream staging tables into the final target table.